Usando a primeira e a última versão do Git do Torvalds
Introdução
Talvez uma das histórias mais conhecidas do mundo Open Source é o nascimento do Git: Linus Torvalds precisava de um sistema de controle de versão para o kernel Linux e nos deu o Git. Enquanto até hoje ele é o mantenedor do kernel, ele foi o mantenedor do Git por apenas três meses, de abril a julho de 2005. Desde então, o Git é mantido por Junio Hamano.
Mesmo após 20 anos desde a troca de liderança, o Git ainda é lembrado como a segunda obra-prima de Linus Torvalds. Pessoalmente, acredito que o que torna o Git excelente é seu elegante núcleo que existe desde sua primeira versão que seja o principal presente que Linus nos deu.
Porém, o quão usável era o Git quando o Torvalds ainda era o mantenedor? Veremos isso aqui, olhando para duas versões do Git:
- O primeiro commit
- A última release feita pelo Torvalds
Então, vamos ver o que aconteceu nesse momento da história do Git.
Setup
Voltemos no tempo. Minha máquina do tempo é o Ubuntu 7.10 Gutsy Gibbon, lançado in 2007. Ele é velho o suficiente para ter pacotes nas versões que o Git antigo precisa e, por sorte, encontrei uma imagem Docker para isso. Eu realmente queria usá-lo no meu Linux moderno, porém, não é tão fácil compilá-lo por conta dessas incompatibilidades de bibliotecas.
É bem fácil obter o código-fonte das versões antigas do Git. Ele é, obviamente, versionado com Git e suas primeiras versões ficarão guardadas para sempre em seu histórico:
git clone git@github.com:git/git.git
cd git
# Listando os commits do mais velho para o mais novo. Queremos o primeiro
git log --reverse
# Listando as versões anteriores à 1.0. Queremos a última lançada por Torvalds
git tag --list 'v0.*'
Tentaremos usar o Git antigo para versionar um simples fizzbuzz em C:
- Primeiro commit: um código C simples apenas com
#include <stdio.h>e a funçãomain - Segundo commit: o laço com o print
- Terceiro e quarto commit: commits paralelos, um adicionando fizz e o outro buzz
- Quinto commit: merge de fizz e buzz:
Este é o grafo de commits que queremos:
* merge
|\
| * buzz
* | fizz
|/
* for
* initial
Este é o código do fizzbuzz, escrito de uma forma que evita conflitos de merge:
#include <stdio.h>
void print(int i) {
int fizzbuzz = 0;
// números fizz
if (i % 3 == 0) {
printf("fizz");
fizzbuzz = 1;
}
// números buzz
if (i % 5 == 0) {
printf("buzz");
fizzbuzz = 1;
}
// outros números
if (!fizzbuzz)
printf("%d", i);
putchar('\n');
}
int main() {
int i;
for (i = 0; i < 100; i++)
print(i);
return 0;
}
Primeira versão: “o gerenciador de informações do inferno”
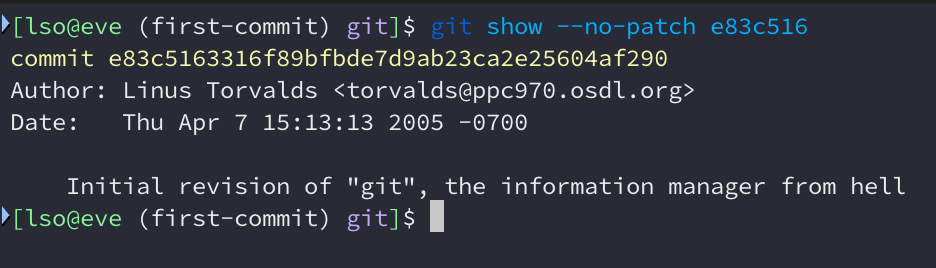
Voltemos ao primeiro commit do Git, e83c5163. Só 9 arquivos, um Makefile e um
README. Apenas 1036 linhas de código C. Havia alguns pequenos problemas no
código e não foi possível compilar apenas com make. Felizmente, os problemas
eram fáceis de corrigir (
aqui está o código corrigido
).
Primeira coisa estranha que notei é que ele não cria um executável chamado
git. Em vez disso, ele cria 7 executáveis:
init-db: equivalente agit initupdate-cache: equivalente agit update-indexougit-addshow-diff: mais ou menos parecido com umgit diffno diretório de trabalhocat-file: equivalente agit cat-file -t+git cat-file -p, redirecionando a saída para um arquivo temporáriocommit-tree: equivalente agit commit-treeread-tree: equivalentegit read-treewrite-tree: equivalente agit write-tree
Deles, o primeiro não existe mais, ao menos não no seu nome original. Os últimos 4 ainda existem como comandos plumbing de baixo nível.
Ok, podemos brincar com ele.
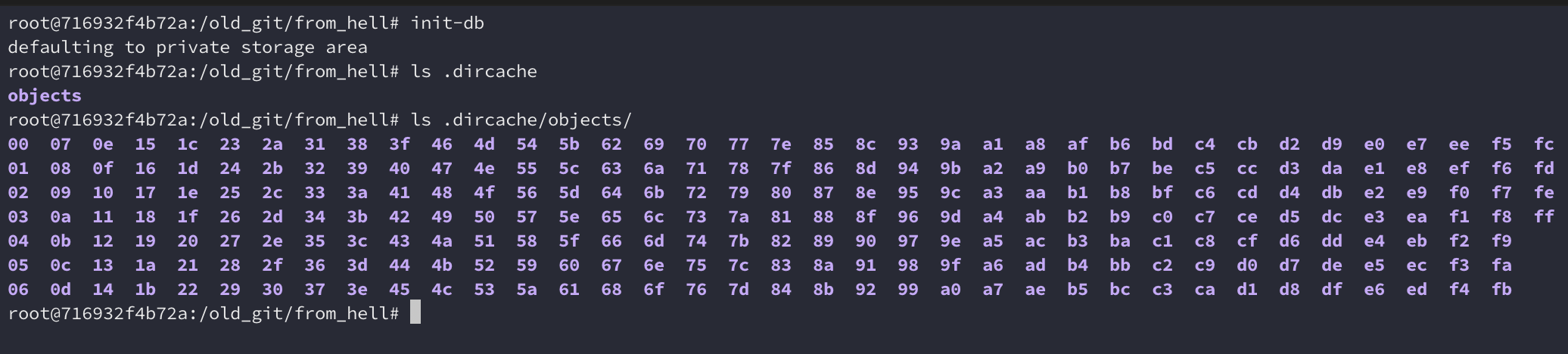
Inicializando
Primeiramente, inicializei um repositório com init-db. Ele me mostrou uma
mensagem misteriosa “defaulting to private storage area”. Em vez de criar um
diretório .git, ele criou um diretório .dircache contendo apenas um
diretório objects parecido com o .git/objects, porém,
contendo todos os diretórios 00~ff por padrão:
Adicionando um código C simples ao index
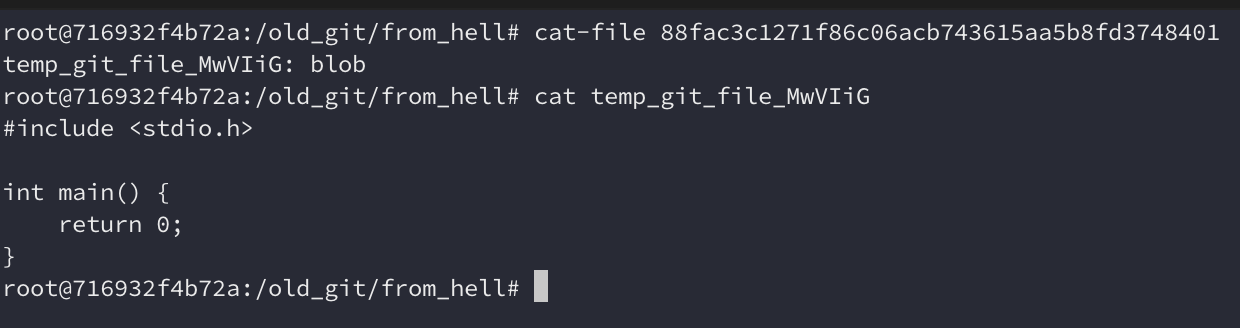
Antes de criarmos um commit, precisamos adicionar nossos arquivos à área de
staging (o index). Usamos update-cache para fazer isso, da mesma como hoje
fazemos com git add:
update-cache fizzbuzz.c
Podemos ver que agora temos um arquivo fac3c1271f86c06acb743615aa5b8fd3748401
dentro de .dircache/objects/88, o que significa que foi criado um objeto
88fac3c1271f86c06acb743615aa5b8fd3748401. No Git moderno poderíamos
inspecioná-lo com git cat-file -p e ver os conteúdos desse objeto. Nesta
primeira versão é necessário usar cat-file e ele mostra que o objeto é um blob
(um conteúdo de um arquivo) e ele cria um arquivo temporário com seu conteúdo:
Um novo arquivo index foi criado dentro de .dircache, assim como temos no
Git modeno. Não temos um comando para inspecioná-lo (como git status ou git
ls-files). Podemos usar hexdump aqui e ele mostra que esse arquivo mapeia
fizzbuzz.c ao blob criado. Então, parece estar tudo funcionando.
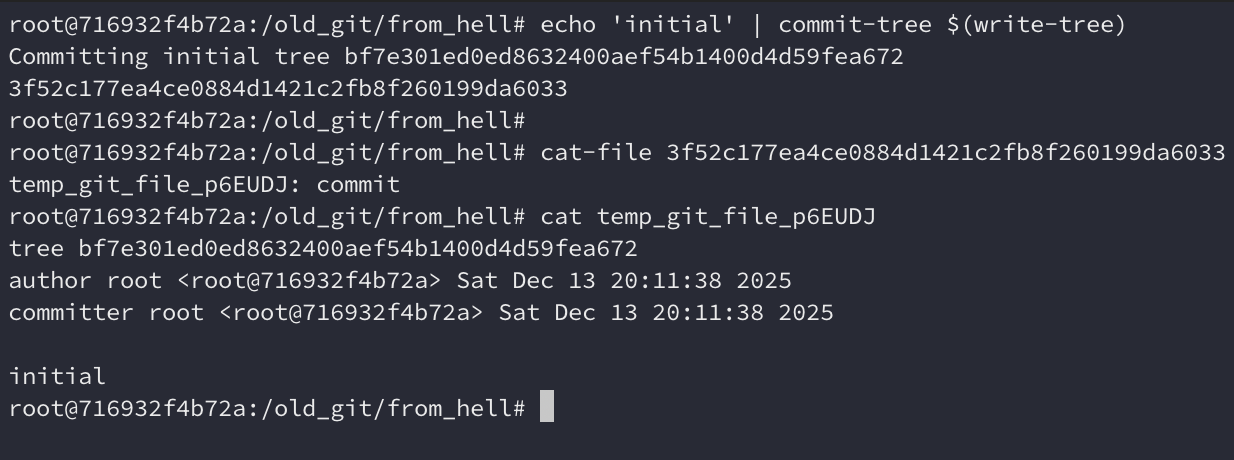
Criando um commit
Queremos agora criar um commit. Não temos git commit aqui, mas podemos fazer
isso de forma manual da mesma forma que no Git moderno poderíamos fazer com
git write-tree + git commit-tree (
mais infos aqui
). Essa versão já tem versões primitivas desses dois comandos, então vamos
usá-los.
Podemos ver através de cat-file que o commit foi criado com sucesso. Ele é
bastante similar aos commits modernos, porém, podemos ver que ele armazena as
datas e horas como texto em vez de um timestamp com timezone.
Dessa forma, a sequência git add + git commit seria:
# git add fizzbuzz.c
update-cache fizzbuzz.c
# git commit -m "my commit"
echo "my commit" | commit-tree $(write-tree) -p <parent commit>
Restaurando o conteúdo
Não temos git restore, git reset ou git checkout aqui, então se quisermos
obter uma versão anterior de um arquivo precisamos fazê-lo atravées de
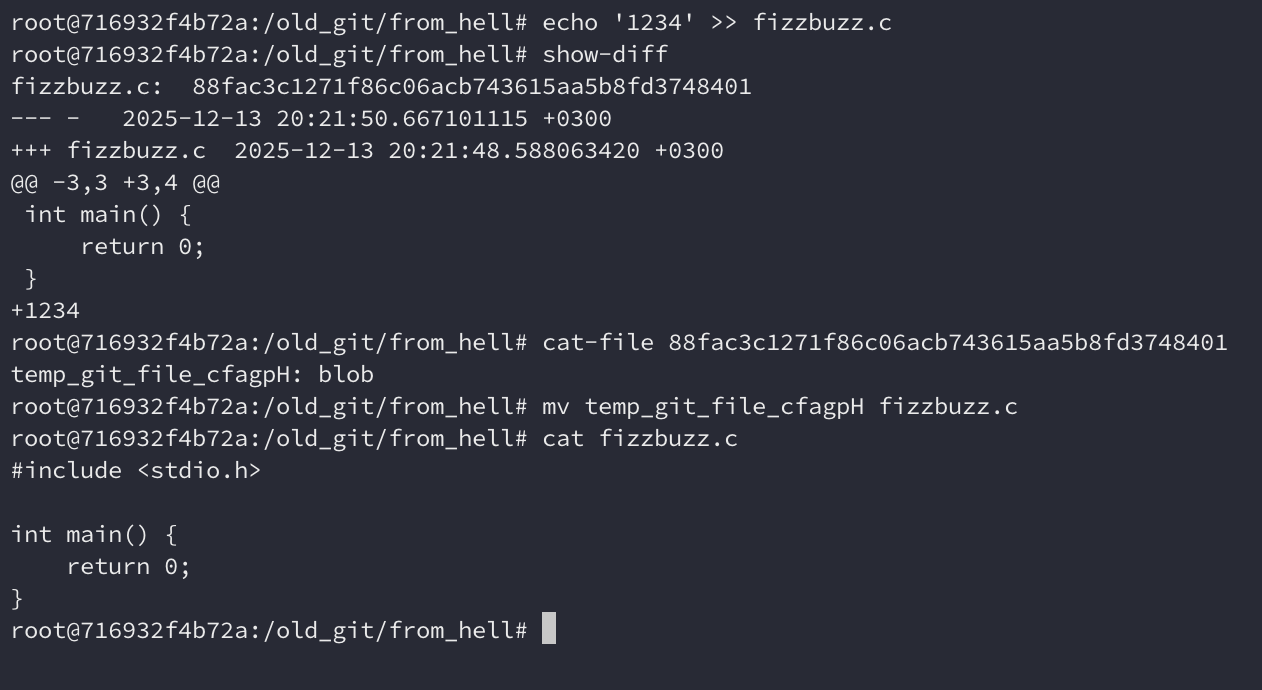
cat-file. Vamos alterar o fizzbuzz.c e tentar restaurá-lo. show-diff nos
mostra o diff em relação ao index, podemos usá-lo para ver as diferenças. Então,
é possível restaurar usando cat-file, mas para isso precisamos do hash do
blob.
Mas e se quisermos restaurar o conteúdo de outro commit, como normalmente
fazemos com git checkout? Precisamos obter o commit, depois sua tree e por
fim, olhar os conteúdos da tree com hexdump, assim:
commit_content=$(cat-file <commit> | cut -d ':' -f 1)
tree_hash=$(cat $commit_content | head -n 1 | cut -d ' ' -f 2)
hexdump -C $(cat-file $tree_hash | cut -d ':' -f 1)
Em nosso setup temos apenas um arquivo, então a tree só tem uma única entrada.
Desta forma, os últimos 20 bytes são o hash do blob que queremos. Se usarmos
cat-file para obter esse blob, podemos renomear o arquivo como fizzbuzz.c.
blob_hash=$(tail -c 20 < $(cat-file $tree_hash | cut -d ':' -f 1) | xxd -p)
mv $(cat-file $blob_hash | cut -d ':' -f 1) fizzbuzz.c
Criando os outros commits
A única diferença próximos commits antes do merge é que eles precisam
referenciar seu commit pai. Podemos fazer isso usando a mesma sequência de
update-cache, write-tree e commit-tree, porém, usando -p <pai> no
commit-tree, da mesma forma que no git commit-tree moderno.
Nosso histórico de commits está assim:
* buzz
| * fizz
|/
* for
* initial
Merge
Ainda não há um algoritmo de merge, temos que mesclar os arquivos manualmente e
criar o commit de merge. O commit de merge é um commit com dois pais, então
podemos usar a mesma sequência, mas fornecendo dois -p <parent> ao
commit-tree.
Compatibilidade
Chegou a hora de saber se o repositório é compatível com um Git moderno (estou
usando 2.50.1). Podemos copiar o arquivo index e o diretório objects do
.dircache para um .git novo. Vamos ver o que acontece.
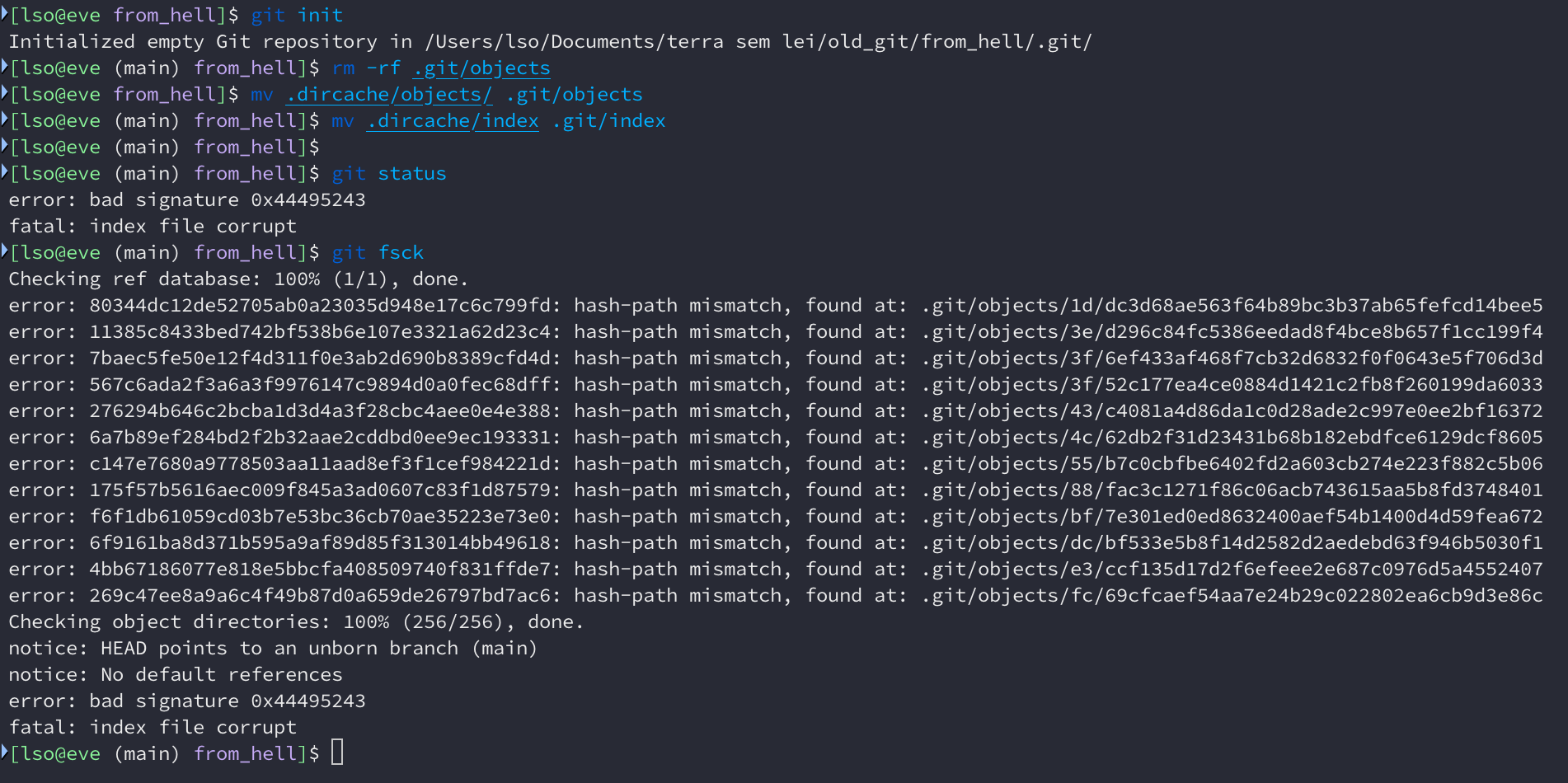
Ah não, todos os arquivos copiados são considerados quebrados pelo Git.
git log até funciona, mas git checkout não.
HEAD e branches
Talvez você reparou que eu não mencionei nada sobre branches ou o commit atual
(HEAD). E isso é porque esses conceitos não existem ainda. Nós apenas operamos
a nível de objetos e index. É necessario saber o hash de cada commit.
É usável?
Nem um pouco. Mesmo se você souber bem como manipular objetos do Git, você precisará copiar os hash toda hora. É difícil de saber o que está acontecendo com esses comandos primitivos e a falta de referências torna tudo realmente difícil. Para ser um pouco mais usável você precisa escrever scripts para manipular os objetos.
A última versão do pai do Git
O primeiro commit é fácil de encontrar, mas e quanto à última versão lançada por Linus Torvalds? Precisamos ir um pouco mais fundo na história do Git e no histórico de Git do Git para encontrar o que aconteceu.
Nossa primeira pista é a mensagem “Meet the new maintainer” enviada do Linus para a lista de email do Git. Ela foi enviada em 15 de julho de 2005, apenas três meses após o primeiro commit. Podemos verificar as tags de release próximas a essa data e ver quem as gerou:
v0.99aponta para um commit feito pelo Junio, mas ainda assinado pelo Linus. Essa tag não tem nenhuma informação de autor porque isso ainda não tinha sido implementado, ainda ia levar alguns dias até que a informação do tagger ser introduzida aqui!v0.99.1tem Linus como autor e é a última versão antes do e-mail “Meet the new maintainer”v0.99.2tem Junio como autor e é assinado por ele
Dessa forma, Linus só criou duas release do Git: v0.99 (em 10 de julho) e
v0.99.1 (em 15 de julho, apenas 5 dias depois). A primeira versão do Junio
(v0.99.1) foi lançada apenas duas semanas depois. Vale a pena notar que
v0.99.1 é a última versão com Linus como maintainer, mas não a última em
que ele esteve envolvido. Na verdade, você pode ver com
git log --author='Linus Torvalds' que ele enviou vários patches desde então.
v0.99.1 já tem o executável git, mas ele é apenas um script para chamar
outros comandos. Você verá que essa versão é muito mais familiar. Ele cresceu
bastante em tamanho, já tendo 20292 linhas de código C, 1092 linhas de código
Perl e 8673 linhas de shellscripts (incluindo testes).
Da mesma forma que o primeiro commit, ele não compila na primeira
tentativa. Precisei remover o git-http-push do Makefile, já que eu não
precisava dele e ele estava quebrando o build.
Inicializando
Agora todos os comandos estão debaixo do comando git, da mesma forma que o
Git moderno (ainda que possamos chamar eles diretamente). Também agora
git init-db gera um diretório .git contendo a HEAD e o diretório refs
(onde ficam as branches e tags). Nesta versão, HEAD é um symlink para a branch
que ela aponta, ao contrário de outras versões mais novas do Git onde ela é um
arquivo de texto puro.
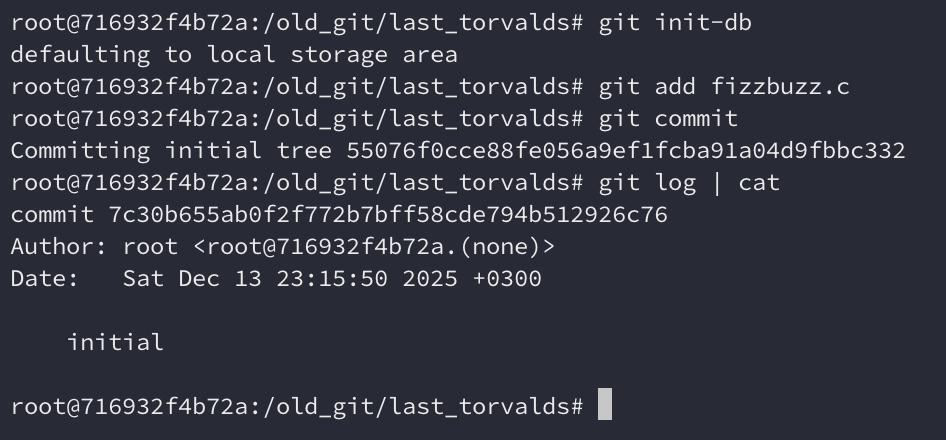
Adicionando ao index and criando commits
Nesta versão, o Git já tem git add e git commit. git status existe, mas
não funciona se não temos pelo menos um commit no nosso histórico. Também temos
git log, mas ela não mostra o nome da branch.
Restaurando os conteúdos de um arquivo
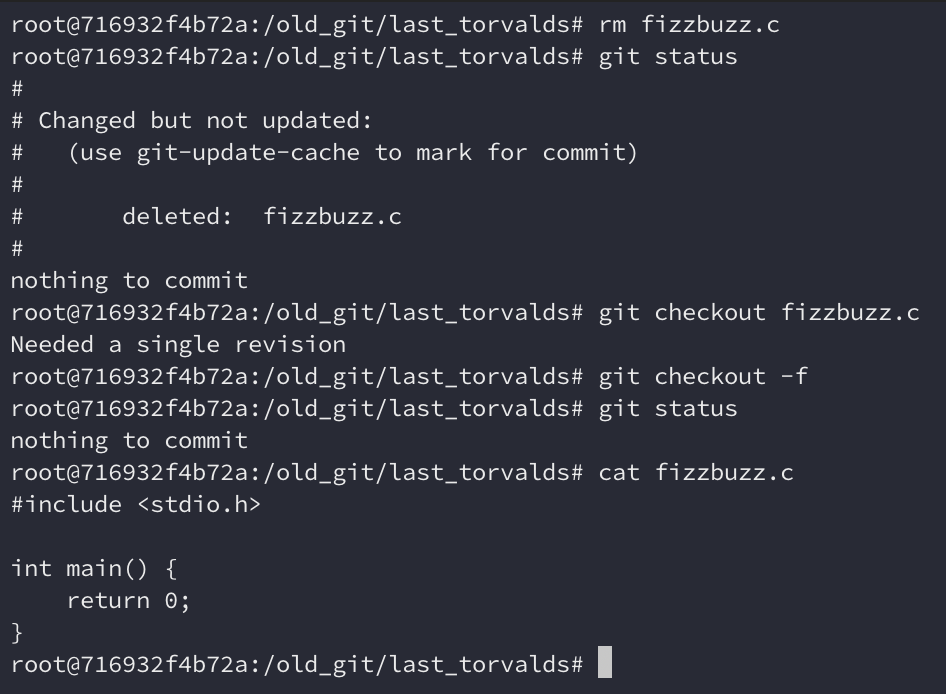
Se tivermos um commit, git status funciona. Ele nos diz que fizzbuzz.c foi
deletado, e que podemos restaurá-lo usando git checkout -f. Legal.
Criando outros commits e branches
Como já temos git add e git commit, não precisamos ficar brincando com
comandos plumbing para criar novos commits. Também podemos criar novas branches
com git checkout -b ou git branch e navegar entre eles usando
git checkout, então essa etapa é realmente como se estivéssemos usando o Git
moderno. O git checkout, porém, ainda não consegue entrar em detached HEAD.
Porém, git rev-parse, git log e git branch não mostram o conteúdo da
branch atual e git-symbolic-ref também não existe ainda. A única forma que
consegui descobrir a branch atual foi olhando direto o link simbólico .git/HEAD.
Merge
git merge ainda não existe, mas o README diz como fazer um merge manual usando
git read-tree. Também temos um script que o Linus escreveu para tornar isso
mais fácil, chamado git resolve. Internamente, ele depende do comando merge
do GNU RCS, então precisamos dele instalado.
Ele conseguiu mesclar as duas branches corretamente.

Compatibilidade
Aparentemente tudo parece funcionar normal quando abro este repositório com o Git 2.50. Mas este repositório é bem simples e com um único arquivo, não sei o que acontece com repositórios mais complexos.
É usável?
Se você sabe o que está fazendo, esta versão já é usável. Mas você precisa realmente saber o que está fazendo, as mensagens de erro não ajudam muito. Outros recursos importantes do Git ainda não foram implementados, então, mesmo que ele seja familiar, é necessário entender o funcionamento interno do Git para usá-lo.
Conclusão
É sempre legal ver o nascimento de algo grandioso. A primeira versão do Git era apenas um conjunto simples de utilitários para manipular alguns arquivos, mas já continha o miolo que torna o Git excelente. A última versão do Git do Torvalds já era muito mais usável e, mesmo que ainda parecesse um tanto frágil, já parecia ser usável o suficiente para ser usada por alguém que realmente sabia o que estava fazendo. Linus certamente sabia e o usou para versionar o Linux.
Ainda que o Linus Torvalds seja lembrado como o pai do Git, a última versão sob sua liderança não era exatamente o Git que conhecemos hoje em dia. Porém, é claro, isso foi um começo incrível e é impressionante o que ele e a comunidade construíram nesses três primeiros meses.