AMQP Broker
Isto foi uma tarefa da disciplina de Programação para Redes de Computadores que eu cursei no primeiro semestre do meu mestrado. Eu gostei bastante do resultado, então achei que valia a pena mencioná-lo aqui.
A ideia era criar um servidor em C que deveria interpretar e processar mensagens do protocolo AMQP, usado em message brokers como o RabbitMQ. Criptografia e tolerância a falhas não eram requisitos, então, não foram implementados. Isso significa que este código é um brinquedo, e não deveria ser usado para aplicações reais.
Como requisitos técnicos, ele deveria:
- ser compatível com AMQP 0.9.1;
- aceitar conexões de desconexões de clientes;
- ser capaz de criar filas;
- aceitar conexões de vários clientes ao mesmo tempo;
- permitir que clientes se inscrevam em uma fila;
- permitir que clientes enviem mensagens para uma fila;
- suportar apenas caracteres ASCII;
- funcionar em GNU/Linux;
O código está disponível no GitHub. Você pode encontrar instruções sobre ele no README.
Desenvolvimento
O código foi escrito baseado na especificação do AMQP. Além disso, também observei a troca de mensagens entre os clientes e o servidor usando o sniffer Wireshark, então, ele foi parcialmente desenvolvido como uma engenharia reversa do RabbitMQ.
Como clientes, usei a suíte de ferramentas de linha de comando amqp-tools,
disponível nos repositórios da maior parte das distribuições Linux e no Homebrew.
Design detalhado
Estruturas de dados
Filas
As filas foram definidas como listas encadeada. Esses são seus nós:
typedef struct q_node {
struct q_node *parent;
int length;
char body[1];
} q_node;
Note que o último campo (o corpo de uma mensagem em uma fila) é um array de char
com apenas um elemento. Isso é porque esse nó de lista ligada também é um
array flexível. Isso é uma
técnica para alocar dinamicamente um array em C junto de outros campos (neste
caso, o ponteiro para o próximo nó e e o tamanho do corpo) em apenas uma
chamada, assim:
q_node *n;
int length = strlen(body);
n = malloc(sizeof(*n) + length * sizeof(char));
n->parent = NULL;
n->length = length;
strcpy(n->body, body);
Aqui, o malloc aloca tamanho suficiente para os campos de uma struct e o
número de caracteres da string body. O byte usado para o null terminator
já está na struct (o 1 em body[1]).
Tries
Tries são estruturas de dados que eu sempre achei muito elegantes mas eu nunca tive um caso de uso que eu precisasse delas. Então, está foi a primeira vez que eu implementei uma.
Ah, e se você não sabe o que é uma trie, você pode ler sobre elas na Wikipedia. Elas são árvores usadas para criar tabelas de símbolos em que as chaves são strings. Cada caractere da string vira um nó da árvore, e o nó do último caractere da string tem uma referência para o valor.
Aqui eu usei tries para indexar as árvore pelo seus nomes. Na imagem a seguir,
eu tenho duas filas chamadas CAFE e CASA. Os nós da trie estão em azul, a
parte fixa dos nós estão em verde e a parte flexível deles estão em vermelho:
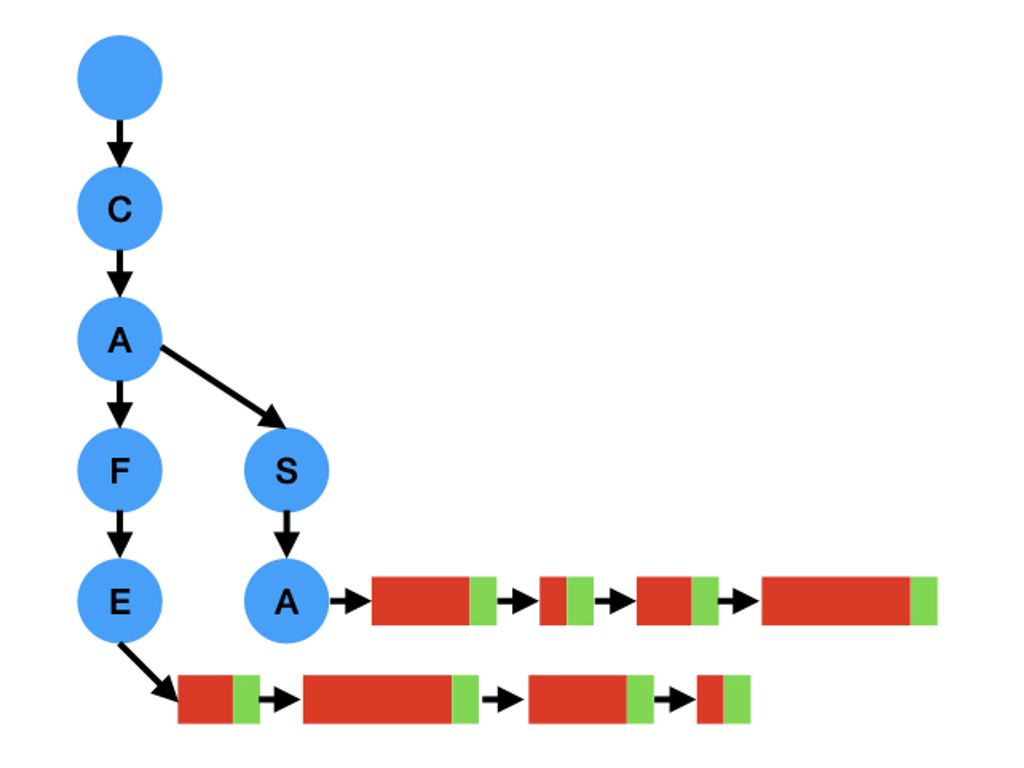
Essas duas estruturas de dados são as únicas alocadas dinamicamente. Evitei
mallocs neste código, assim não precisei me preocupar muito com vazamentos de
memória.
Mensagens
Escrever um código em C tem suas vantagens, principalmente devido a C estar em um nível mais baixo em relação a outras linguagens de baixo nível. Uma coisa que isso me ajudou muito aqui é que eu não precisei escrever um parser muito complexo para ler as mensagens AMQP. O protocolo AMQP define campos de tamanho fixo que podem ser representados como campos em uma struct em C. Isso significa que, para a maior parte dos casos, foi suficiente declarar a estrutura, como eu fiz aqui:
/* Message header. The header of an amqp message (except protocol header). */
typedef struct {
uint8_t msg_type;
uint16_t channel;
uint32_t length;
} __attribute__((packed)) amqp_message_header;
E em seguida copiar os dados brutos direto para o endereço de memória dessa struct, e tratando o endianness dos campos, assim:
static int parse_message_header(char *s, size_t n, amqp_message_header *header) {
size_t header_size = sizeof(amqp_message_header);
if (n < header_size) return 1;
memcpy(header, s, header_size);
header->channel = ntohs(header->channel);
header->length = ntohl(header->length);
return 0;
}
Se você está se perguntando o que __attribute__((packed)) significa, isso é
necessário para evitar padding.
Máquina de estados
Isto foi na maior parte copiado do README. Perdão pelos diagramas ASCII, mas o README foi escrito para mostrado em um terminal, e iria levar muito tempo para refazê-lo em SVG, então estou deixando do jeito que eles estavam.
Como o AMQP é um protocolo com estados, uma forma de manter o controle da comunicação com o cliente é usando uma máquina de estados.
Cada máquina de estados é criada após o início da conexão com o cliente, e inicia no estado WAIT, onde espera o cabeçalho do protocolo (Protocol Header).
O último estado da conexão é o FINISHED, em que a conexão é encerrada sem problemas. Há ainda um estado FAIL, para qual qualquer outro estado pode ir caso ocorra algum erro.
Diagrama da máquina de estados
O estado FAIL é omitido aqui para simplificar o diagrama, já que qualquer estado pode ir para ele caso encontre algum problema.
Os estados durante o estabelecimento da conexão são os seguintes:
*--------* *------------* *------------*
| WAIT | -------------------> | HEADER | --------> | WAIT |
| | C: Protocol Header | RECEIVED | S: Start | START OK |
*--------* *------------* *------------*
|
C: Start OK |
|
*-----------------* *-----------* *------------* |
| WAIT |<---------- | WAIT | <-------- | START OK | <--
| OPEN CONNECTION | C: Tune Ok | TUNE OK | S: Tune | RECEIVED |
*-----------------* *-----------* *------------*
|
| C: Open Connection
|
| *-----------------* *-----------------*
--> | OPEN CONNECTION | ----------------------> | OPEN CONNECTION |
| RECEIVED | S: Open Connection OK | RECEIVED |
*-----------------* *-----------------*
|
C: Open Channel |
|
*-------------* *--------------* |
| WAIT | <--------------------- | OPEN CHANNEL | <---
| FUNCTIONAL | S: Open Channel OK | RECEIVED |
*-------------* *--------------*
|
| C: Método
|
|-> Fluxo de declação de filas
|
|-> Fluxo de publicação
|
-> Fluxo de consumo
A partir do estado WAIT FUNCTIONAL, podemos ter 3 fluxos diferentes: o da declaração de filas, o da publicação e o do consumo, ou ainda, iniciar o fechamento de uma conexão.
Esses fluxos podem iniciar o encerramento da conexão dentro de seus estados, o que também será omitido aqui para simplificar o diagrama.
O fluxo da declaração de filas é o seguinte:
*------------* *---------------*
| WAIT | -------------------> | QUEUE DECLARE |
| FUNCTIONAL | C: Queue Declare | RECEIVED |
| | | |
| | <------------------ | |
| | S: Queue Declare OK | |
*------------* *---------------*
O fluxo da publicação é o seguinte:
*------------* *---------------* *----------------*
| WAIT | -------------------> | BASIC PUBLISH | -> | WAIT PUBLISH |
| FUNCTIONAL | C: Basic Publish | RECEIVED | | CONTENT HEADER |
*------------* *---------------* *----------------*
^ |
C: Basic Publish | C: Content Header |
| |
| *----------------* |
|-------- | WAIT PUBLISH | <-
| | CONTENT |
-------> | |
C: Body | |
*----------------*
O fluxo do consumo é o seguinte:
*------------* *---------------*
| WAIT | ----------------> | BASIC CONSUME |
| FUNCTIONAL | C: Basic Consume | RECEIVED |
*------------* *---------------*
|
| S: Basic Consume OK *------------*
---------------------> | WAIT VALUE |
-----------------------------------------> | DEQUEUE |
| C: Consume Ack *------------*
| |
| |
| Q: Dequeue |
| |
*--------------* *---------------* |
| WAIT CONSUME | <------------------- | VALUE DEQUEUE | <--
| ACK | S: Basic Deliver | RECEIVED |
| | S: Content Header | |
| | S: Body | |
*--------------* *---------------*
Quanto ao encerramento, ele pode ser iniciado em alguns estados quando eles recebem mensagens de encerramento de canal ou de conexão:
*---------------* *-----------*
----------------> | CLOSE CHANNEL | -------------------> | WAIT OPEN |
C: Close Channel | RECEIVED | S: Close Channel OK | CHANNEL |
*---------------* *-----------*
*------------------* *----------*
-------------------> | CLOSE CONNECTION | ----------------------> | FINISHED |
C: Close Connection | RECEIVED | S: Close Connection OK | |
*------------------* *--------- *
Experimentos
A análise do desempenho foi parte do trabalho, e acho que é legal mostrar aqui como curiosidade. Não quero ser muito científico aqui.
Ambiente
O ambiente era composto por três computadores de placa única velhos (duas Beaglebones e uma Raspberry Pi) chamadas Emerson, Lake e Palmer (te considero meu amigo se você sabe quem são eles), meu computador antigo (chamado Wall-e), e um velho roteador Linksys WRT54G.
Meu notebook mais novo (chamado Eve, e sim, porque o mais velho se chamava Wall-e) não fez parte do experimento porque ele é muito mais poderoso e eu queria ver tudo sendo executado em máquinas mais fracas. Serviu apenas para fazer o acesso remoto para as máquinas do experimento.
Essas são as especificações das máquinas e seus papéis :
| Maquina | CPU | Número de núcleos | RAM | Sistema Operacional | Tipo de conexão | Papel no experimento |
|---|---|---|---|---|---|---|
| Wall-e | Intel core i5 | 2 | 8GB | Manjaro Linux | Cabeada | Servidor |
| Eve | Apple M1 | 8 | 8GB | Mac OS Monterey | WiFi | Acesso remoto |
| Emerson | ARM Cortex A8 | 1 | 230MB | Debian Buster | Cabeada | Publisher |
| Lake | ARM Cortex A8 | 1 | 484MB | Debian Buster | Cabeada | Publisher |
| Palmer | BCM2835 | 1 | 432MB | Debian Bullseye | Cabeada | Consumer |
E sobre a rede, o comando iperf nos mostra que o throughput entre Emerson e
Wall-e e entre Lake e Wall-e era de aproximadamente 94Mb/s, e entre Palmer e
Wall-e era de aproximadamente 53Mb/s.
Observações
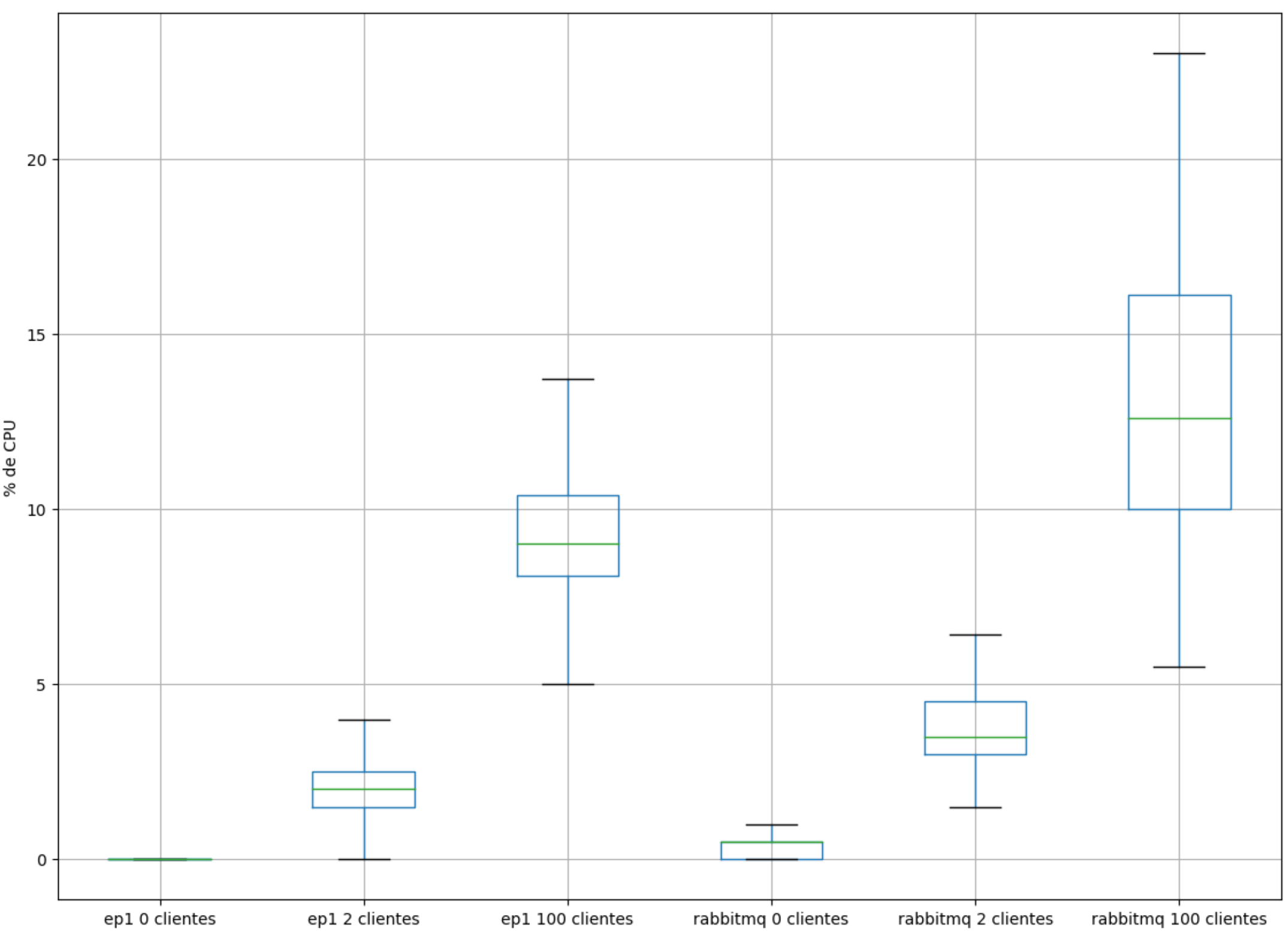
CPU
Comparando o uso de CPU deste servidor AMQP e o RabbitMQ, podemos ver que este teve uma performance levemente melhor em 0, 2 e 100 clientes conectados (o servidor desenvolvido aqui está nomeado como “ep1” nos gráficos).
Rede
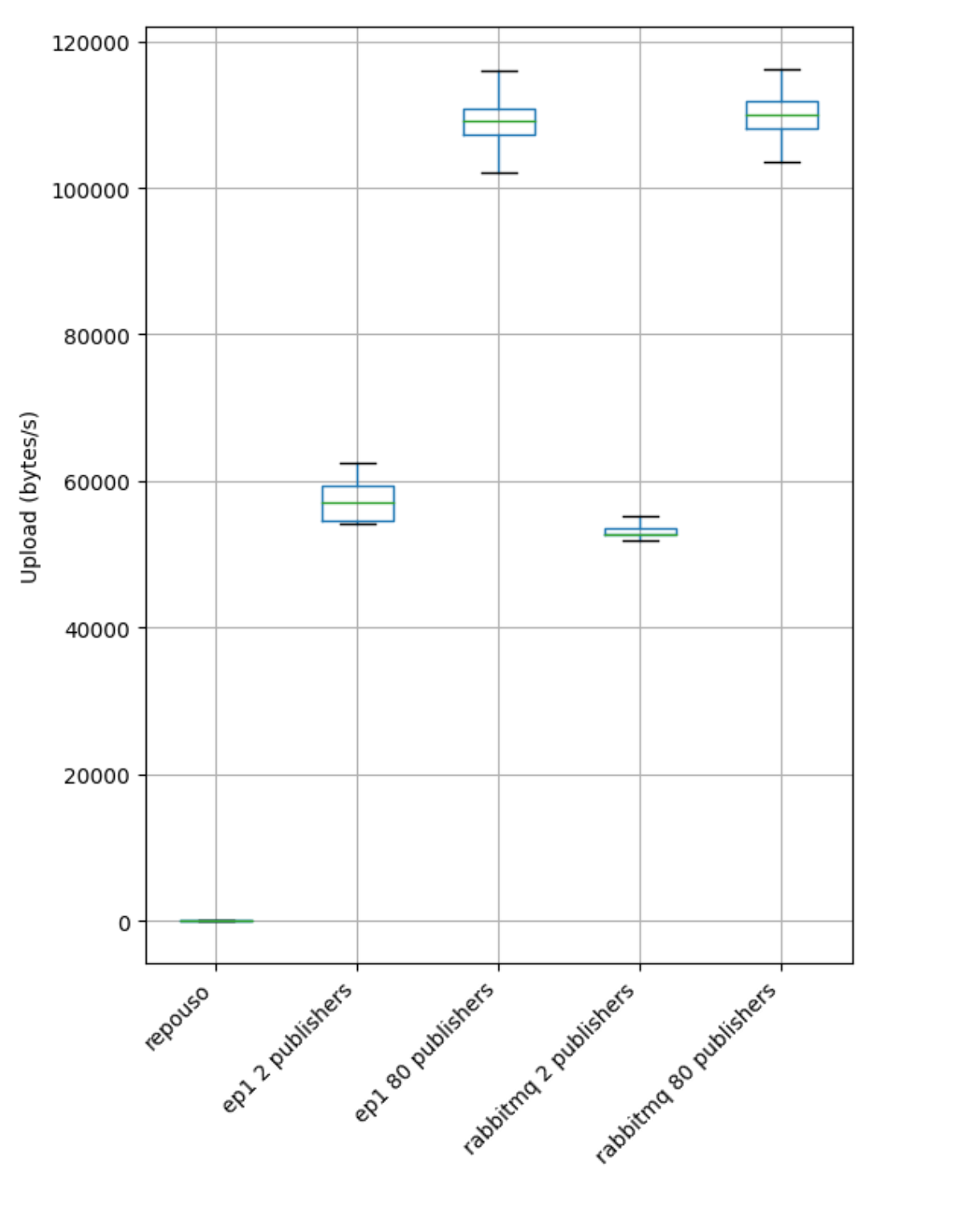
Comparando a taxa de upload de um máquina que atua como publisher, em ambos os servidores ela se manteve mais ou menos a mesma:
Comparando a taxa de download da máquina consumer, nós podemos ver que o RabbitMQ envia mais dados por segundo:
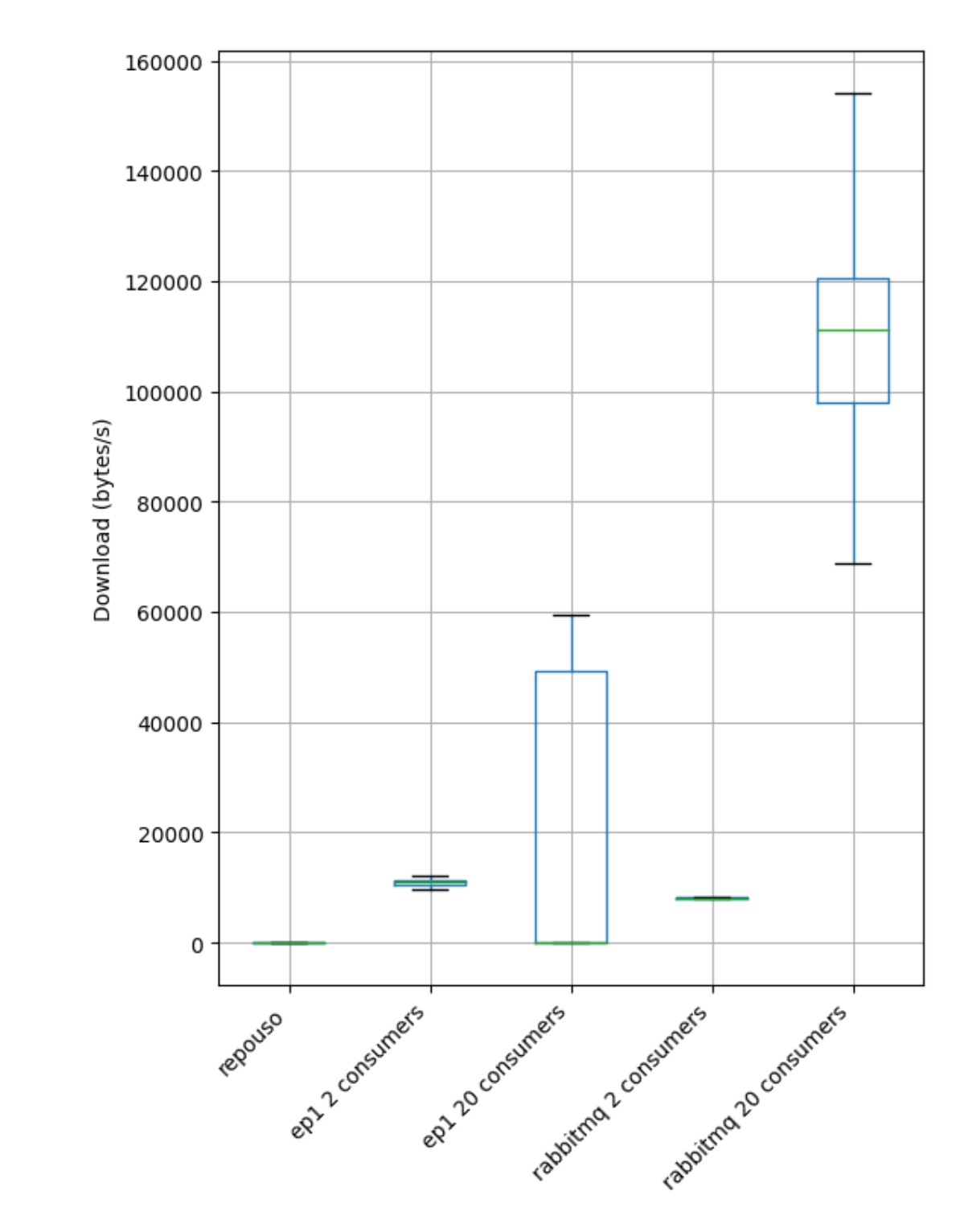
RabbitMQ é o vencedor aqui!
Conclusão
Este foi um exercício bem difícil e que demandou muito tempo para entender o protocolo, para desenvolver e para fazer os experimentos. Mas sinceramente, eu gosto desse tipo de coisa que reinventa a roda porque isso me faz entender de forma mais profunda como as coisas funcionam. Eu nunca tinha usado o RabbitMQ diretamente antes, e agora tudo ficou mais claro já que eu sei o que acontece por debaixo dos panos.
Se você acha que o desempenho foi muito bom para um projeto simples feito por apenas uma pessoa, tenha em mente que isto é extremamente simples comparado ao verdadeiro RabbitMQ. Vários recursos do RabbitMQ (por exemplo, channels, exchanges, criptografia, autenticação) estão faltando.
Lembre-se também que o RabbitMQ é executado em uma máquina virtual Erlang, enquanto este servidor é compilado para um binário nativo, então, é esperado que este use menos recursos quando tem pouca demanda. Porém, isso não significa que o desempenho dele seja melhor, já que é possível ver que o RabbitMQ pôde entregar mais dados por segundo.