Git: please stop squash merging!
Intro
It says “20 minute read”.
If you’re thinking “it’s easy, I’ll keep squashing so I can save those 20 minutes of my life”, well, I must say that it is not an excuse, you can stop squashing right now without reading this. But if you still thinking that using squash merging is a good idea, please, keep reading this. You’ll probably won’t want to squash your anymore after reading this, except in some very specific cases (and those cases probably are not what you’re expecting).
This is long and dense, so, no more intro. Here we go!
Goals
- Explain what squash merges actually are, detailing how Git works under the hood;
- Show how the most well-known “pros” about squash merging are conceptually wrong;
- Show situations that squash merges can be harmful;
- Show what you can (and should) do instead of using squash merge;
Non-goals
- Tell something that works for me and dictating that it will also work for you;
- Create another “good practice guide” for people follow without questioning if is true. Be skeptical;
Why do you use squash merge?
If you consider that squash merge is a good practice, have you ever thought why it is a good practice? Or are you only repeating something that you have heard?
Be honest.
In the past, I also thought it was cool, but as I studied Git a little deeper soon I figured out that it doesn’t make sense. Not only that, but it is never mentioned as good practice in Git documentation, not even as a practice:
-
Pro Git (the official Git book) has two chapters and a appendix about merge and it barely mentions squash in the merge context (it only mentions here and here, using squash only as an intermediate tool);
-
Apart from
git mergemanpage and Pro Git, the official Git documentation only mentions squash in gitfaq, focusing on the problems of doing that; -
Last but not least, Git itself doesn’t have a single “squash and merge” command, you have to run two commands to perform it (we’ll discuss about that later).
So, before we go deeper, I need you to ask you two things:
First, what do you think that a squash merge is?
(go ahead, write it, it’s only a textarea without any hidden JavaScript)
Second, why do you think you should do it, given the first answer?
Ok, thanks! We’ll come here later. Now, before I tell you why you shouldn’t squash your commits (and before you squash your commits again), we need to have it clear what a squash actually is. And I must say most people who squash do it because they don’t know what a squash merge is. And, again, I must say this is because they have two major misconceptions about Git.
There’s where we start.
The first misconception: what a commit stores
I strongly recommend you that you read Pro Git, the official Git book. For our purposes here, section 1.3 and chapter 10 will be enough. But by now what we need to know from it is that Git commits don’t store changes. They store snapshots.
Repeat after me: “Git commits don’t store changes, they store snapshots”.
And that’s the first misconception. When we’re using commands such as git show,
git diff or external tools such as the Pull Request UI on GitHub we think
that commits are sets of changes of states. But no, each commit is a state
plus some metadata.
Under the hood, Git stores the repository data in the so-called objects. Each object stores data and is identified by its SHA-1 hash. Roughly saying, we have three main types of objects:

- Blob: contains file contents;
- Tree: represents a directory. It is a list of files or directories, the hash of their contents (a blob if it is a file or a tree if it is a directory) and their file permissions;
- Commit: contains the author, the commiter, its timestamp , its message, its parents and the snapshot
It is important to say that the child commit points to its parent or parents, but the parent commit doesn’t point to its children. The first commit doesn’t have any parent, and a merge commit has two parents or more. In the case of merge commits, the parent order matters.
The snapshot of a commit is just the tree object that represents the root directory of the commit when it was created.
Perhaps you are thinking: “that is not possible, that would be a waste of disk space”. But that it is not true: a file that hasn’t changed between two commits has the same content in both states, so their contents are stored in the same blob. This is also true for directories.
And if you’re thinking “this is not true, I saw something about deltas, those are the commit changes”, yeah, those deltas are changes but they are not changes between commits. They are related to a compresion that Git does using something called packfile, but you don’t need to know about them by now. Only keep in mind that Git somehow compresses the objects, so the disk space is not something you should care too much.
Just one more thing: branches ares not objects. They are references, that is, only pointers to commits. This is, there’s no such thing as “a commit is in a branch”, as a branch is not a set of commits as we may think. But it is very common to say that, even though it is not 100% correct. It is just a shorter way to say “the commit is an ancestor of the commit pointed by the branch”.
For now on, sometimes I’ll refer to a commit pointed by a branch as just “a branch”.
I disccussed a little more about objects here, but again, I strongly suggest you to read about that on Pro Git for more datailed info.
How merge works
Now that we know what a commit and a branch are, we can proceed to see how merge works.
In Git, by “merge” we can think as three things, at least:
- The command
git merge - A merge commit (i.e. a commit with two or more parents)
- The mechanism used by
git mergeto join the contents of both branches
When you run git merge <another branch>, you tell Git to join the contents of
both branches and create a merge commit. The merge commit will have as the first
parent the one pointed by the current HEAD and the commit pointed by the
merged branch as its second parent.

When the commit of the current branch is a direct ancestor of the commit of the
merged branch, Git will perform a fast-forward. Fast forwards don’t create
merge commits, they only make the current branch point to the same commit as the
merged branch, so they are not true merges. You can change this behaviour by
using --no-ff. GitHub also provides a feature for merging PRs without
fast-forwarding them in those cases. Personally, I don’t like fast-forwards, so
I use no fast forward when possible.
So, by now we know what is 1 (git merge) and 2 (merge commit), but what about
3? What is the mechanism that Git uses to join the files of both branches? Well,
Git performs an algorithm called three-way merge that uses the snapshots of
three commits in order to figure out what should be kept in the merge commit and
what should not:
- the commit pointed by the current branch (named A);
- the commit pointed by the branch that we want to merged (named B);
- the commit that is the last common ancestor between A and B (named O).
When performing a three-way merge, Git will keep everything that are the same in A and B. If there’s something different, it will compare O and A, and O and B. If something doesn’t changed from O to A but changed from O to B, it keeps the change introduced in B, and vice-versa. If O, A and B differ, then we have a conflict and you need to manually fix it.
This picture shows how the three-way merge works. Different colors means different contents of a file:

Note: for plaintext files, if there’s a conflict Git will perform three-way merge comparing the lines, so it can merge the contents of a file that don’t overlap. If there’s a overlap, then it puts the conflict marks.
This mechanism is also used in other commands, such as cherry-pick, revert, rebase and stash, but this is a topic for another post.
This is really brief explanation about merge and there’s a lot to talk about (e.g. how Git handles renames, file permissions, submodules and so on). Here I discussed a little more about merge, but by now this is enough.
As an exercise: try to imagine how hard and expensive merge would be if Git stored changes instead of snapshots.
What squash merge actually is
By now, we know what is a merge. But how about a squash merge? I just googled “why squash merge?” and I found these definitions about what it is:
-
“Instead of each commit on the topic branch being added to the history of the default branch, a squash merge adds all the file changes to a single new commit on the default branch”
-
“It turns all your changes into one single commit and then adds that to the main branch”
-
“By squashing commits, developers can condense a series of small, incremental changes into a single meaningful change”
-
“Squashing retains the changes but discards all the individual commits”
Well, time to revisit your answer. Click here to see it. Is your answer similar to those? Well, I ask you that because there’s something that all those answers have in common: they are all wrong!
And they are wrong because, remember: Git commits don’t store changes, they store snapshots.
Again: Git commits don’t store changes, they store snapshots.
Now, an exercise: try to rewrite those answers (or your answer, if it has the same idea) replacing the wrong idea of commits storing changes by the correct idea of commits storing snapshots. Here’s another textarea only for your convenience:
Was it hard? Well, this is because that idea of what a squash merge is is based on a wrong idea of what Git is, and it doesn’t make any sense in real life.
I bet that if you regularly squash merge you do it by using the UI of GitHub or similar, and you never did it locally on your machine through CLI, using this button:
And I say that because, as I said before, there’s no command for squash merging in Git! In fact, in order to do the same thing as the “squash and merge” button on GitHub you’ll need two commands:
git merge --squash another_branch
git commit
Several useful Git commands that are a single command originally were a set of
commands, such as git stash,
git subtree and so on, but this
never managed (at least so far) to be a single command. That should raise an
alert on you that something is out of place here.
Let’s check what happens when we perform a squash merge locally:
-
The first command is the squash itself. It merges the current branch with the other one, but it doesn’t create a merge commit. Instead, it only merges the files (using the mechanism that we discussed before) in the filesystem (in Git jargon, working directory) and stages them just like
git adddoes (in Git jargon, it adds them to the index); -
The second command is just a standard
git commit. When we perform agit commitwe create a new commit after the state of the index (the staging area), that contains the merged files and the untouched ones. The previous step creates a commit message containing a list of the messages of the branch that was squashed, and it is used as template here.
A commit whose contents are a merge of the two merged branches. Hmmmm, sounds familiar? Isn’t it a merge commit?
Oh wait, isn’t it a merge commit????
Are squash merge and standard merge the same??
WHAT???
Please, calm down. They are different. How? Remember that a merge commit has two or more parents? That’s the difference. This commit has only one parent: the commit pointed by the current branch before merging. This way, there’s no reference to the other branch, and that’s the only difference between the squash merge commit and the true merge commit.

Don’t you believe? What more could change?
- The author, commiter, timestamps or message? These are only metadata;
- The snapshot? No, it is the same, as it was generated by the same mechanism.
The only thing left is the parents. Squash merge is the same as the true merge but with a missing information: the reference to the merged branch.
Why is it good?
Is it good?
This leads to the second misconception.
The second misconception: the fallacy of the clean history
I don’t know if you still think that squash is a good idea after knowing what it really is. But anyway, let’s read again why you think that squash merges are good: click here.
Just like I did before, here are some answers from some of the first results after a quick Google search for “why squash merge”:
- “Squash merging keeps your default branch histories clean”
- “Your base branch remains clean”
- “This helps developers to maintain a clean Git commit history”
- “This [squash merging] helps keep your code history clean”
See? It is very common to say that squash merges keeps the history clean. And, was we saw, the only difference between the squash merges and true merges is that squash merges don’t preserve the reference to the original branch, so “clean” in this situation means “less information” and “less commits”. And I ask you: why a commit history with fewer commits are the better? Here’s another textar… (no, enough textareas!)
If it was true, the best commit history would be not commiting at all. So, the best way to use Git would be not using Git. Something is wrong here.

That is our second misconception. Cleaner commit histories are better, indeed, but a history with fewer commits is not cleaner. So, what is a good commit history?
A good commit history
A good commit history is a history that contains good commits.
Personally, I’m intrigued that it is a common sense that most developers agree that code quality and data quality are important while it is harder to find someone that really cares about the code repository quality. And the repository is the database where we store code.

Lets recap some practices that we commonly associate with code quality:
- Code that is easy to understand;
- Code that implements simple solutions;
- Code that is easy to debug, when needed;
- Code that is simple;
- Code that can be tested;
- Code that follow the same codestyle;
- Good documentation.
And about data quality:
- Data that is easy to retrieve;
- Data that is accurate;
- Data that is clean.
I don’t want to write a commit guideline here, but there is a lot of good resources that you can read about. I’ll leave some of them at the bottom of this page. I don’t think that you should follow them as a religion (I think that you should follow them as long as them make sense), but there are some practices that worth be mentioned here:
- Atomic changes: each commit should introduce an indivisible codeset;
- Write good commit messages: use the commit message to describe the change you introduced;
- Don’t commit incomplete work: if it is not ready, then don’t commit (use the staging area);
And we if we do that, we’ll have more commits, but they will be good commits. They will be meaningful and they will be easier to debug with tools such as the ones that I mentioned here. Not only that, it will be easier to cherry-pick and revert specific changes.
There are some commit guidelines, I don’t think that you need to adopt any specific one, but you can take a look a decide if they make sense to you. Or they can be a inspiration for you create your own:
-
the Linux kernel, that is the project that Git was created for has a strict guideline for writing patches (commits that are sent by email). I also had a patch that was rejected by doing too much, and I need to rewrite my history and send again.
-
the conventional commits specification is less strict then the Linux kernel, as several projects follow them;
-
Gitmoji is similar to conventional commits, but it uses emoji to identify the commit types (for good or for bad).
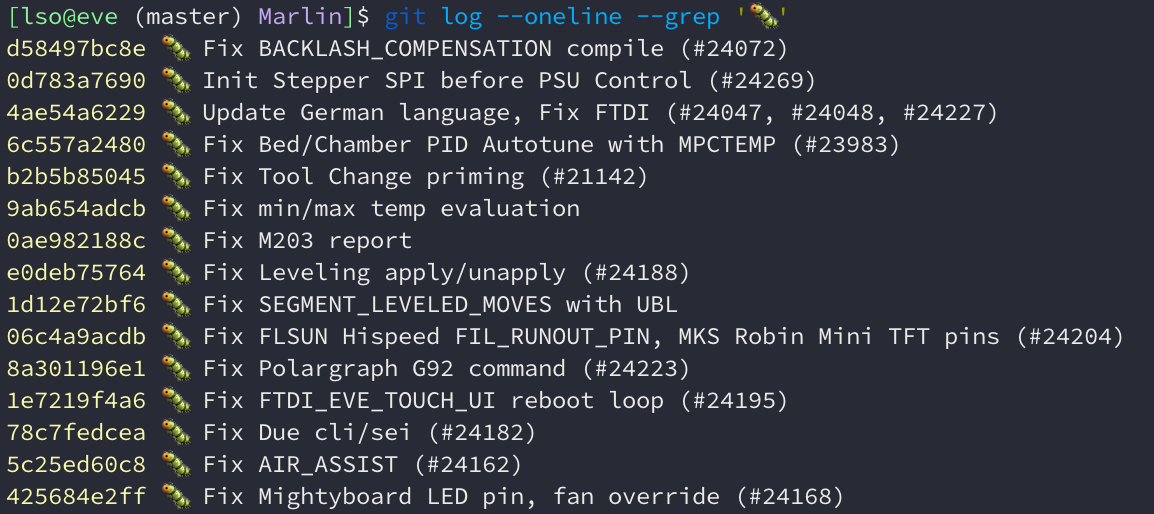
For example, Marlin, a firmware for 3D printers, uses Gitmoji. Look how it is easy to find commits with bugfixes:
Last but not least: don’t fear rewriting history. Of course it can be dangerous, but you can use it in your favor to create a clean commit history. I suggest you to read this. I also suggest you to include commit history reviewing to your code reviewing process, just like the Linux kernel does (and rejecting bad commit histories like they did with me!).
When squash can be evil
I think I have enough evidence for you to see that squash is not exactly something good and the arguments to use it are based on wrong principles of what Git is and what are a so called clean history. But if you asking if there’s a case where squash merges can break something, I once saw it silently breaking a repository with submodules as a consequence of not having the reference of the merged branch.
At first I started to write about that situation but I thought it will make this article even longer than it already is, so I wrote another article only about it here.

So, what should I do?
If you are used to perform squash merges probably you are thinking “what should I do?”, because it still feels comfortable to keep squashing even though you they are not the best choice. Let’s do the right things from now on.
But squashing makes my life so easy…
Let’s imagine you are driving a car with manual transmission. You have 5 forward gears and one reverse. Do you think it is a good idea to drive your car backwards because you don’t want to shift gears? I hope you don’t, and I hope that you at least suspect that the car have 5 gears instead of 1 because things are not so easy and pretending they are easy is not the solution (err… unless you drive an automatic).
And here it is the same. We need to understand our tools and how to use them.
Some people say: “if you squash you have a linear history, only seeing the merge commits”. Ok, but you can see it without squashing (and without losing the original commits) by running:
git log --first-parent
“Squash merges are easy to revert”:
git revert -m 1 <commit>
“Squash merges are easy to cherry-pick”:
git cherry-pick -m 1 <commit>
“Squash merges are easy to <insert something>”: read the documentation about
how to do something properly! No excuses!
If you are convinced…
Here are some things that you can do:
-
Try to write meaningful commits like we discussed before. It is hard at first, but it will soon become easy and it will pay your effort;
-
On you code reviews, also review the commit history. Check if it is clean and, if it is not, ask to the author of the code to rewrite the history, just like you would do with code;
-
If you are a junior developer, listen to the seniors developers but don’t take everything that they say as true. Question everything, and that will make you grow;
-
If you are a senior, don’t tell juniors to do something that you aren’t certain that is right and that you believe that it is right because another senior told you to do that when you were a junior. Don’t be a parrot;
-
The same applies here. Question everything that I said. Don’t do anything only because I told here.
If you are not convinced…
I tried to do my best.
Is there any good use case for squash merge?
Oh yeah, of course. It is a tool just like many others that Git has, so of course it can be useful! But there are a lot of more useful Git tools that people generally don’t know, for example, some searching and debugging tools that I explained here.
I stopped to think for about two minutes in a use case for squash. And here it is one: supposing that you have an old branch with only one commit diverging from your main. Now you want to merge it, but the main branch changed so much that the code would need to be compatible with those changes.

An option here is to rebase foo onto main, make the code compatible with the
new main, and then git commit --amend. Other is to cherry-pick foo (in
practice, it would be the same as rebasing). But you can also do this:
git checkout main
git checkout -b bar
git merge --squash foo
# edit the code in order to make it compatible
git commit
In that situation, we’re using git merge --squash to apply the changes
introduced in foo to our files, without commiting. Then we make the code
compatible and create a new commit.

And that’s it. A simple tool that may be useful in very specific situations.
Conclusion
Thanks for your time! I hope that this may be useful. If something is wrong, please open a issue.
And for the last time, remember: Git commits don’t store changes, they store snapshots!
Further reading
The references that I mentioned in this text are listed here.
For general Git information:
- Pro Git by Scott Chacon: It’s the official Git Book. I’ll select the sections that are most important here.
About Git internals:
- Pro Git - What is Git: explains what Git is and compares it with delta-based versioning systems;
- Pro Git - Git Internals: explains how Git works under the hood.
About merge:
- Wikipedia - Merge (version control): explains merge and three way merge
About commiting:
- How to Write a Git Commit Message by cbeams: Advices about what to put in a commit message;
- Git 101 by Matheus Tavares: it’s a general presentation about Git but it focus on commits after slide 29;
- Pro Git - commit guidelines: chapter of Pro Git about how to commit;
- Philosophy of Linux kernel patches: about patches (commits) in the Linux Kernel;
- Conventional Commits v1.0.0: a convention about commits that is adopted by several projects;
- Gitmoji: similar to conventional commits, but using emoji.
About rewriting history:
- Git: Rewriting History 101 by Matheus Tavares: about when, how and why rewrite the commit history;
- Pro Git - rewriting history: Chapter of Pro Git about rewriting history.
About squash merging (note that both discuss about the fallacy of the clean history):
- Squash commits considered harmful by Manuel Odendahl. After writing some sections here I found this article that is quite similar;
- Squash merges are evil by L. Holanda. Another good article against squash merge.
Other articles about Git that I wrote: